Getting Started¶
This tutorial provides a quick overview of GraphScope’s features. To begin, we will install GraphScope on your local machine using Python. Although most examples in this guide are based on local Python installation, it also works on a Kubernetes cluster.
You can easily install GraphScope through pip:
python3 -m pip install graphscope -U
Note
We recommend you to install GraphScope in a clean Python virtual environment with Python 3.9 with miniconda or venv.
Take venv for an example, there’s a step by step instruction to create a virtual environment, activate the environment and install GraphScope:
# Create a new virtual environment
python3.9 -m venv tutorial-env
# Activate the virtual environment
source tutorial-env/bin/activate
# Install GraphScope
python3.9 -m pip install graphscope
# Use GraphScope
python3.9
>>> import graphscope as gs
>>> ......
One-stop Graph Processing¶
We will use a walking-through example to demonstrate how to use GraphScope to process various graph computation tasks in a one-stop manner.
The example targets node classification on a citation network.
ogbn-mag is a heterogeneous network composed of a subset of the Microsoft Academic Graph. It contains 4 types of entities (i.e., papers, authors, institutions, and fields of study), as well as four types of directed relations connecting two entities.
Given the heterogeneous ogbn-mag data, the task is to predict the class of each paper. Node classification can identify papers in multiple venues, which represent different groups of scientific work on different topics. We apply both the attribute and structural information to classify papers. In the graph, each paper node contains a 128-dimensional word2vec vector representing its content, which is obtained by averaging the embeddings of words in its title and abstract. The embeddings of individual words are pre-trained. The structural information is computed on-the-fly.
GraphScope models graph data as property graph, in which the edges/vertices are labeled and have many properties. Taking ogbn-mag as an example, the figure below shows the model of the property graph.
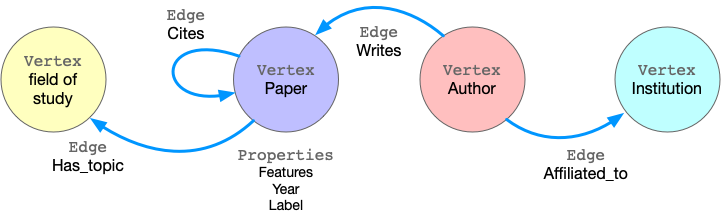
Sample of property graph¶
This graph has four kinds of vertices, labeled as paper, author, institution, and field_of_study. There are four kinds of edges connecting them, each kind of edge has a label and specifies the vertex labels for its two ends. For example, cites edges connect two vertices labeled paper. Another example is writes, it requires the source vertex is labeled author and the destination is a paper vertex. All the vertices and edges may have properties. e.g., paper vertices have properties like features, publish year, subject label, etc.
Import GraphScope and load a graph
To load this graph to GraphScope with our retrieval module, please use these code.
import graphscope
from graphscope.dataset import load_ogbn_mag
g = load_ogbn_mag()
Interactive queries enable users to explore, examine, and present graph data in a flexible and in-depth manner, allowing them to find specific information quickly. GraphScope enhances the presentation of interactive queries and ensures efficient execution of these queries on a large scale by providing support for the popular query languages Gremlin and Cypher.
Run interactive queries with Gremlin and Cypher
In this example, we use graph traversal to count the number of papers two given authors have co-authored. To simplify the query, we assume the authors can be uniquely identified by ID 2 and 4307, respectively.
# get the endpoint for submitting interactive queries on graph g.
interactive = graphscope.interactive(g)
# Gremlin query for counting the number of papers two authors (with id 2 and 4307) have co-authored
papers = interactive.execute("g.V().has('author', 'id', 2).out('writes').where(__.in('writes').has('id', 4307)).count()").one()
# Cypher query for counting the number of papers two authors (with id 2 and 4307) have co-authored
# Note that for Cypher query, the parameter of lang="cypher" is mandatory
papers = interactive.execute( \
"MATCH (n1:author)-[:writes]->(p:paper)<-[:writes]-(n2:author) \
WHERE n1.id = 2 AND n2.id = 4307 \
RETURN count(DISTINCT p)", \
lang="cypher")
Graph analytics is widely used in the real world. Many algorithms, like community detection, paths and connectivity, and centrality, have proven to be very useful in various businesses. GraphScope comes with a set of built-in algorithms, enabling users to easily analyze their graph data.
Run analytical algorithms on the graph
Continuing our example, we first derive a subgraph by extracting publications within a specific time range from the entire graph (using Gremlin!). Then, we run k-core decomposition and triangle counting to generate the structural features of each paper node.
Please note that many algorithms may only work on homogeneous graphs. Therefore, to evaluate these algorithms on a property graph, we need to project it into a simple graph first.
# extract a subgraph of publication within a time range
sub_graph = interactive.subgraph("g.V().has('year', gte(2014).and(lte(2020))).outE('cites')")
# project the projected graph to simple graph.
simple_g = sub_graph.project(vertices={"paper": []}, edges={"cites": []})
ret1 = graphscope.k_core(simple_g, k=5)
ret2 = graphscope.triangles(simple_g)
# add the results as new columns to the citation graph
sub_graph = sub_graph.add_column(ret1, {"kcore": "r"})
sub_graph = sub_graph.add_column(ret2, {"tc": "r"})
Graph neural networks (GNNs) combines superiority of both graph analytics and machine learning. GNN algorithms can compress both structural and attribute information in a graph into low-dimensional embedding vectors on each node. These embeddings can be further fed into downstream machine learning tasks.
Prepare data and engine for learning
In our example, we train a supervised GraphSAGE model to classify the nodes (papers) into 349 categories, each representing a venue (e.g., pre-print or conference). To accomplish this, we first launch a learning engine and construct a graph with features, following the previous step.
# define the features for learning
paper_features = [f"feat_{i}" for i in range(128)]
paper_features.append("kcore")
paper_features.append("tc")
# launch a learning engine.
lg = graphscope.graphlearn(sub_graph, nodes=[("paper", paper_features)],
edges=[("paper", "cites", "paper")],
gen_labels=[
("train", "paper", 100, (0, 75)),
("val", "paper", 100, (75, 85)),
("test", "paper", 100, (85, 100))
])
Then we define the training process, and run it.
Define the training process and run it
try:
# https://www.tensorflow.org/guide/migrate
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except ImportError:
import tensorflow as tf
import graphscope.learning
from graphscope.learning.examples import EgoGraphSAGE
from graphscope.learning.examples import EgoSAGESupervisedDataLoader
from graphscope.learning.examples.tf.trainer import LocalTrainer
# supervised GraphSAGE.
def train_sage(graph, node_type, edge_type, class_num, features_num,
hops_num=2, nbrs_num=[25, 10], epochs=2,
hidden_dim=256, in_drop_rate=0.5, learning_rate=0.01,
):
graphscope.learning.reset_default_tf_graph()
dimensions = [features_num] + [hidden_dim] * (hops_num - 1) + [class_num]
model = EgoGraphSAGE(dimensions, act_func=tf.nn.relu, dropout=in_drop_rate)
# prepare train dataset
train_data = EgoSAGESupervisedDataLoader(
graph, graphscope.learning.Mask.TRAIN,
node_type=node_type, edge_type=edge_type, nbrs_num=nbrs_num, hops_num=hops_num,
)
train_embedding = model.forward(train_data.src_ego)
train_labels = train_data.src_ego.src.labels
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=train_labels, logits=train_embedding,
)
)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# prepare test dataset
test_data = EgoSAGESupervisedDataLoader(
graph, graphscope.learning.Mask.TEST,
node_type=node_type, edge_type=edge_type, nbrs_num=nbrs_num, hops_num=hops_num,
)
test_embedding = model.forward(test_data.src_ego)
test_labels = test_data.src_ego.src.labels
test_indices = tf.math.argmax(test_embedding, 1, output_type=tf.int32)
test_acc = tf.div(
tf.reduce_sum(tf.cast(tf.math.equal(test_indices, test_labels), tf.float32)),
tf.cast(tf.shape(test_labels)[0], tf.float32),
)
# train and test
trainer = LocalTrainer()
trainer.train(train_data.iterator, loss, optimizer, epochs=epochs)
trainer.test(test_data.iterator, test_acc)
train_sage(lg, node_type="paper", edge_type="cites",
class_num=349, # output dimension
features_num=130, # input dimension, 128 + kcore + triangle count
)
Graph Analytical Task Quick Start¶
The installed graphscope package includes everything you need to analyze a graph on your local machine. If you have a graph analytical job that needs to run iterative algorithms, it works well with graphscope.
Example: Running iterative algorithm (SSSP) in GraphScope
import graphscope as gs
from graphscope.dataset.modern_graph import load_modern_graph
gs.set_option(show_log=True)
# load the modern graph as example.
#(modern graph is an example property graph given by Apache at https://tinkerpop.apache.org/docs/current/tutorials/getting-started/)
graph = load_modern_graph()
# triggers label propagation algorithm(LPA)
# on the modern graph(property graph) and print the result.
ret = gs.lpa(graph)
print(ret.to_dataframe(selector={'id': 'v.id', 'label': 'r'}))
# project a modern graph (property graph) to a homogeneous graph
# and run single source shortest path(SSSP) algorithm on it, with assigned source=1.
pg = graph.project(vertices={'person': None}, edges={'knows': ['weight']})
ret = gs.sssp(pg, src=1)
print(ret.to_dataframe(selector={'id': 'v.id', 'distance': 'r'})
Graph Interactive Query Quick Start¶
With the graphscope package already installed, you can effortlessly engage with a graph on your local machine.
You simply need to create the interactive instance to serve as the conduit for submitting Gremlin or Cypher queries.
Example: Run Interactive Queries in GraphScope
import graphscope as gs
from graphscope.dataset.modern_graph import load_modern_graph
gs.set_option(show_log=True)
# load the modern graph as example.
#(modern graph is an example property graph given by Apache at https://tinkerpop.apache.org/docs/current/tutorials/getting-started/)
graph = load_modern_graph()
# Hereafter, you can use the `graph` object to create an `interactive` query session, which will start one Gremlin service and one Cypher service simultaneously on the backend.
g = gs.interactive(graph)
# then `execute` any supported gremlin query.
q1 = g.execute('g.V().count()')
print(q1.all().result()) # should print [6]
q2 = g.execute('g.V().hasLabel(\'person\')')
print(q2.all().result()) # should print [[v[2], v[3], v[0], v[1]]]
# or `execute` any supported Cypher query
q3 = g.execute("MATCH (n:person) RETURN count(n)", lang="cypher", routing_=RoutingControl.READ)
print(q3.records[0][0]) # should print 6
Graph Learning Quick Start¶
GNN model training with GraphScope is easy and straightforward. You can use the graphscope package to train a GNN model on your local machine. Note that
tensorflow is required to run the following example.
Example: Training GraphSAGE Model in GraphScope
import graphscope
from graphscope.dataset import load_ogbn_mag
g = load_ogbn_mag()
# define the features for learning
paper_features = [f"feat_{i}" for i in range(128)]
# launch a learning engine.
lg = graphscope.graphlearn(g, nodes=[("paper", paper_features)],
edges=[("paper", "cites", "paper")],
gen_labels=[
("train", "paper", 100, (0, 75)),
("val", "paper", 100, (75, 85)),
("test", "paper", 100, (85, 100))
])
try:
# https://www.tensorflow.org/guide/migrate
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
except ImportError:
import tensorflow as tf
import graphscope.learning
from graphscope.learning.examples import EgoGraphSAGE
from graphscope.learning.examples import EgoSAGESupervisedDataLoader
from graphscope.learning.examples.tf.trainer import LocalTrainer
# supervised GraphSAGE
def train_sage(graph, node_type, edge_type, class_num, features_num,
hops_num=2, nbrs_num=[25, 10], epochs=2,
hidden_dim=256, in_drop_rate=0.5, learning_rate=0.01,
):
graphscope.learning.reset_default_tf_graph()
dimensions = [features_num] + [hidden_dim] * (hops_num - 1) + [class_num]
model = EgoGraphSAGE(dimensions, act_func=tf.nn.relu, dropout=in_drop_rate)
# prepare train dataset
train_data = EgoSAGESupervisedDataLoader(
graph, graphscope.learning.Mask.TRAIN,
node_type=node_type, edge_type=edge_type, nbrs_num=nbrs_num, hops_num=hops_num,
)
train_embedding = model.forward(train_data.src_ego)
train_labels = train_data.src_ego.src.labels
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=train_labels, logits=train_embedding,
)
)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# prepare test dataset
test_data = EgoSAGESupervisedDataLoader(
graph, graphscope.learning.Mask.TEST,
node_type=node_type, edge_type=edge_type, nbrs_num=nbrs_num, hops_num=hops_num,
)
test_embedding = model.forward(test_data.src_ego)
test_labels = test_data.src_ego.src.labels
test_indices = tf.math.argmax(test_embedding, 1, output_type=tf.int32)
test_acc = tf.div(
tf.reduce_sum(tf.cast(tf.math.equal(test_indices, test_labels), tf.float32)),
tf.cast(tf.shape(test_labels)[0], tf.float32),
)
# train and test
trainer = LocalTrainer()
trainer.train(train_data.iterator, loss, optimizer, epochs=epochs)
trainer.test(test_data.iterator, test_acc)
train_sage(lg, node_type="paper", edge_type="cites",
class_num=349, # output dimension
features_num=128, # input dimension
)